ByteBuf
在介绍ByteBuf之前先来一套基础的代码来演示ByteBuf的使用。
package blossom.project.netty;
import io.netty.buffer.ByteBuf;
import io.netty.buffer.Unpooled;
import java.nio.charset.StandardCharsets;
/**
* @author: ZhangBlossom
* @date: 2023/12/14 13:37
* @contact: QQ:4602197553
* @contact: WX:qczjhczs0114
* @blog: https://blog.csdn.net/Zhangsama1
* @github: https://github.com/ZhangBlossom
* ByteBufTest类
*/
public class ByteBufTest {
public static void main(String[] args) {
// 创建一个新的ByteBuf实例
ByteBuf buffer = Unpooled.buffer(10);
System.out.println("Initial capacity: " + buffer.capacity());
// 写入一些数据到ByteBuf中
String data = "hello";
buffer.writeBytes(data.getBytes(StandardCharsets.UTF_8));
// 打印写索引和读索引
System.out.println("Write index after writing data: " + buffer.writerIndex());
System.out.println("Read index after writing data: " + buffer.readerIndex());
// 读取数据
byte[] readData = new byte[buffer.readableBytes()];
buffer.readBytes(readData);
System.out.println("Data read from ByteBuf: " + new String(readData, StandardCharsets.UTF_8));
// 再次打印写索引和读索引
System.out.println("Write index after reading data: " + buffer.writerIndex());
System.out.println("Read index after reading data: " + buffer.readerIndex());
// 清除ByteBuf(重置读写索引)
buffer.clear();
System.out.println("Write index after clearing: " + buffer.writerIndex());
System.out.println("Read index after clearing: " + buffer.readerIndex());
// 释放ByteBuf
buffer.release();
}
}
从代码中可以看出, ByteBuf的使用主要包含了三个步骤,创建、读、写。
并且可以看到ByteBuf还提供了一个读写索引的机制。
那么接下来我们来先了解一下ByteBuf(bf)的创建。
创建ByteBuf
创建bf有多种方式,上面的代码中只是其中的一种。
Unpooled Buffers
使用 Unpooled 类可以创建非池化的 ByteBuf。这些 ByteBuf 的内存分配和释放是独立的,不依赖于 Netty 的缓冲区池。
// 创建一个具有固定容量的ByteBuf
ByteBuf buffer = Unpooled.buffer(32); // 容量为32字节
// 创建一个包含特定数据的ByteBuf
byte[] data = {1, 2, 3, 4};
ByteBuf bufferWithData = Unpooled.wrappedBuffer(data);
// 创建一个可动态扩展的ByteBuf
ByteBuf dynamicBuffer = Unpooled.dynamicBuffer();
Pooled Buffers
Netty 还提供了字节缓冲区池化的机制,这有助于减少内存分配和垃圾收集的开销。
// 使用PooledByteBufAllocator创建ByteBuf
ByteBuf pooledBuffer = PooledByteBufAllocator.DEFAULT.buffer(32);
Composite ByteBuf
CompositeByteBuf 是一种特殊类型的 ByteBuf,它可以将多个 ByteBuf 实例组合成一个单一的逻辑缓冲区,但在内部它们仍然是独立的缓冲区。
CompositeByteBuf compositeBuffer = Unpooled.compositeBuffer();
compositeBuffer.addComponents(buffer1, buffer2); // 添加多个ByteBuf
compositeBuffer.removeComponent(0); // 移除指定的ByteBuf
ByteBufAllocator
ByteBufAllocator 接口是创建 ByteBuf 的另一种方式。可以使用默认的分配器或自定义的分配器。
// 通过Channel的alloc()获取ByteBufAllocator创建ByteBuf
ByteBufAllocator allocator = channel.alloc();
ByteBuf allocatedBuffer = allocator.buffer(32);
其中我开发中用的比较多的就是这种,ByteBufAllocator。
并且对于这种方式,还有两种代码可以用来创建ByteBuf。
//由JVM来管理内存
ByteBufAllocator.DEFAULT.heapBuffer();
//使用直接内存 也就是堆外内存
ByteBufAllocator.DEFAULT.directBuffer();
ByteBufAllocator.DEFAULT.heapBuffer()
- 堆内存:
- heapBuffer() 方法创建的是一个基于堆内存的 ByteBuf(即数据存储在 JVM 的堆空间中)。
- 这意味着数据可以直接作为 Java 的字节数组访问,这在某些情况下更方便,特别是当需要将数据作为字节数组处理时。
- 内存复制:
- 当需要从堆内存 ByteBuf 将数据发送到网络时,可能需要将数据复制到直接内存中(因为在某些操作系统中,网络 I/O 是在直接内存上进行的)。
- 使用场景:
- 当需要频繁地访问和修改字节数组时,使用堆内存 ByteBuf 更有优势。
ByteBufAllocator.DEFAULT.directBuffer()
- 直接内存:
- directBuffer() 方法创建的是一个基于直接内存的 ByteBuf(即数据存储在 JVM 的堆外,直接在操作系统的内存中)。
- 直接内存访问通常比堆内存更快,尤其是在 I/O 操作中,因为它减少了内存复制。
- 内存复制减少:
- 对于网络 I/O,使用直接内存可以减少或避免将数据从 JVM 堆复制到内核空间的开销,从而提高性能。
- 使用场景:
- 在需要高效进行网络 I/O 操作时,特别是在发送或接收大量数据时,使用直接内存 ByteBuf 更合适。
- 堆内存 ByteBuf (heapBuffer) 适合于需要频繁地作为字节数组处理数据的场景。
- 直接内存 ByteBuf (directBuffer) 更适合于网络 I/O 和大量数据的处理,可以提高性能,但可能在内存管理上更复杂。
在选择使用哪种类型的 ByteBuf 时,需要根据具体的应用场景和性能需求来决定。直接内存 ByteBuf 虽然在 I/O 操作中表现出更高的性能,但它的分配和回收成本通常比堆内存 ByteBuf 更高。
因为直接内存并不由JVM管理,也就是我们需要手动管理,而堆内存由JVM管理,就会减少出现意外的可能性。
ByteBuf结构
在了解bf的读写之前,我们先介绍一下bf的结构,这样子有助于帮助我们了解读写原理。
ByteBuf 的主要结构包括以下几个部分:
- 废弃字节(Discarded Bytes):
- 这部分包含了已经被读取的数据。它们位于 ByteBuf 的开始位置到读索引(readerIndex)之间。
- 可读字节(Readable Bytes):
- 位于读索引(readerIndex)和写索引(writerIndex)之间的部分。这些是尚未读取的数据。
- 可写字节(Writable Bytes):
- 位于写索引(writerIndex)和缓冲区容量(capacity)之间的部分。这部分用于写入新数据。
- 可扩容字节(Expandable Bytes):
- 如果 ByteBuf 是可扩容的,那么在缓冲区容量(capacity)之后可能还有额外的空间用于扩展。
- 读写指针:
- readerIndex 和 writerIndex 分别表示读取和写入操作的当前位置。读操作从 readerIndex 开始,写操作从 writerIndex 开始。
结构大概如下:
+-------------------+------------------+------------------+
| 废弃字节 | 可读字节 | 可写字节 |
| Discarded Bytes | Readable Bytes | Writable Bytes |
+-------------------+------------------+------------------+
| | | |
0 <= readerIndex <= writerIndex <= capacity
- 当从 ByteBuf 中读取数据时,readerIndex 向前移动。
- 当向 ByteBuf 写入数据时,writerIndex 向前移动。当你的添加的数据达到capacity的时候,就会触发扩容。
- capacity 表示 ByteBuf 的当前容量,但对于某些类型的 ByteBuf(如 PooledByteBuf),实际的存储空间可能大于 capacity,这使得它们在需要时可以扩容。
核心方法
了解了上面的简单的概念之后,我们就需要开始了解一些bf相关的重要的API,了解了API的作用之后,配合代码,就可以比较快速的理解这些API的具体使用了。
读取相关方法
- readByte(), readBytes(), readChar(), 等:
- 这些方法用于从 ByteBuf 中读取数据。readByte() 读取单个字节,readBytes() 可以读取多个字节到字节数组或另一个 ByteBuf,readChar() 读取字符等。
- 读取操作会增加 readerIndex。
- readableBytes():
- 返回可读字节的数量,即 writerIndex - readerIndex。
- getByte(), getBytes(), 等:
- 类似于 read* 方法,但不改变 readerIndex。这用于“窥视”数据而不移动读索引。
写入相关方法
- writeByte(), writeBytes(), writeChar(), 等:
- 用于向 ByteBuf 写入数据。writeByte() 写入单个字节,writeBytes() 从字节数组或另一个 ByteBuf 写入多个字节,writeChar() 写入字符等。
- 写入操作会增加 writerIndex。
- writableBytes():
- 返回可写字节的数量,即 capacity - writerIndex。
- setByte(), setBytes(), 等:
- 类似于 write* 方法,但不改变 writerIndex。用于在不移动写索引的情况下修改数据。
索引管理方法
- readerIndex(int) 和 writerIndex(int):
- 设置 ByteBuf 的 readerIndex 和 writerIndex。这允许手动移动读写指针。
- markReaderIndex() 和 resetReaderIndex():
- markReaderIndex() 在当前的 readerIndex 设置一个标记,resetReaderIndex() 将 readerIndex 重置到这个标记。这在需要多次读取同一数据段时非常有用。
- markWriterIndex() 和 resetWriterIndex():
- 类似于读索引的标记和重置,但用于写索引。
这里我用一个demo来展示出对于这些方法的使用:
import io.netty.buffer.ByteBuf;
import io.netty.buffer.ByteBufUtil;
import io.netty.buffer.Unpooled;
import java.nio.charset.StandardCharsets;
public class ByteBufDemo {
public static void main(String[] args) {
// 创建一个ByteBuf实例
ByteBuf buffer = Unpooled.buffer(50);
// 写入一些数据
buffer.writeBytes("Hello, Netty!".getBytes(StandardCharsets.UTF_8));
showByteBuf(buffer);
// 读取一个字节
buffer.readByte();
showByteBuf(buffer);
// 标记当前的readerIndex
buffer.markReaderIndex();
// 读取一些数据
byte[] bytes = new byte[5];
buffer.readBytes(bytes);
showByteBuf(buffer);
// 重置到标记的readerIndex
buffer.resetReaderIndex();
showByteBuf(buffer);
// 写入更多数据
buffer.writeBytes(" More data".getBytes(StandardCharsets.UTF_8));
showByteBuf(buffer);
// 标记当前的writerIndex
buffer.markWriterIndex();
// 再次写入数据
buffer.writeBytes(" Even more data".getBytes(StandardCharsets.UTF_8));
showByteBuf(buffer);
// 重置到标记的writerIndex
buffer.resetWriterIndex();
showByteBuf(buffer);
// 跳过几个字节
buffer.skipBytes(5);
showByteBuf(buffer);
// 释放ByteBuf
buffer.release();
}
private static void showByteBuf(ByteBuf buf) {
StringBuilder sb = new StringBuilder();
sb.append("read index: ").append(buf.readerIndex());
sb.append("\nwrite index: ").append(buf.writerIndex());
sb.append("\ncapacity: ").append(buf.capacity()).append("\n");
ByteBufUtil.appendPrettyHexDump(sb, buf);
System.out.println(sb.toString());
}
}
- writeBytes:
- 每次调用 writeBytes 方法时,writerIndex 会向前移动写入的字节数量。这意味着新写入的数据总是放置在之前写入数据的后面。
- readByte 和 readBytes:
- 类似地,每次调用 readByte 或 readBytes 方法时,readerIndex 会向前移动读取的字节数量。这确保了连续的读取操作不会重复读取相同的数据。
- markReaderIndex 和 resetReaderIndex:
- markReaderIndex 方法用于记录当前的 readerIndex 位置。随后无论如何移动 readerIndex(如通过读取操作),调用 resetReaderIndex 都会将 readerIndex 重置回标记的位置。这在需要多次读取同一数据段时非常有用。
- markWriterIndex 和 resetWriterIndex:
- 这对方法与读索引的标记和重置相似,但用于写索引。markWriterIndex 记录当前 writerIndex 的位置,resetWriterIndex 将 writerIndex 重置回标记的位置。这在撤销写入操作时很有用。
- skipBytes:
- skipBytes 方法用于在不读取数据的情况下向前移动 readerIndex。
其他重要方法
- copy(), duplicate(), slice():
- 用于创建 ByteBuf 的副本或子区域。copy() 创建数据的深拷贝,而 duplicate() 和 slice() 创建视图(共享同一数据)。
- clear():
- 重置 readerIndex 和 writerIndex 为 0,但不清除数据内容。
- capacity() 和 ensureWritable(int):
- capacity() 返回 ByteBuf 的当前容量。ensureWritable(int) 确保 ByteBuf 有足够的写入空间,如有必要,进行扩容。
import io.netty.buffer.ByteBuf;
import io.netty.buffer.ByteBufUtil;
import io.netty.buffer.Unpooled;
import java.nio.charset.StandardCharsets;
public class ByteBufAdvancedDemo {
public static void main(String[] args) {
// 创建一个ByteBuf并写入数据
ByteBuf buffer = Unpooled.buffer(50);
buffer.writeBytes("Hello, Netty!".getBytes(StandardCharsets.UTF_8));
showByteBuf(buffer);
// 使用slice()创建一个新的ByteBuf,共享相同的数据
ByteBuf slicedBuffer = buffer.slice(0, 5);
showByteBuf(slicedBuffer);
// 使用duplicate()复制整个ByteBuf,共享数据
ByteBuf duplicatedBuffer = buffer.duplicate();
showByteBuf(duplicatedBuffer);
// 使用copy()创建ByteBuf的副本,数据不共享
ByteBuf copiedBuffer = buffer.copy();
showByteBuf(copiedBuffer);
// 检查当前容量并扩展ByteBuf
System.out.println("Capacity before ensuring writable: " + buffer.capacity());
buffer.ensureWritable(100);
System.out.println("Capacity after ensuring writable: " + buffer.capacity());
// 释放ByteBuf资源
buffer.release();
slicedBuffer.release();
duplicatedBuffer.release();
copiedBuffer.release();
}
private static void showByteBuf(ByteBuf buf) {
StringBuilder sb = new StringBuilder();
sb.append("read index: ").append(buf.readerIndex());
sb.append("\nwrite index: ").append(buf.writerIndex());
sb.append("\ncapacity: ").append(buf.capacity()).append("\n");
ByteBufUtil.appendPrettyHexDump(sb, buf);
System.out.println(sb.toString());
}
}
- slice():
- 创建原始 ByteBuf 的一个切片,共享相同的数据存储。修改切片中的数据也会影响原始 ByteBuf。
- duplicate():
- 复制整个 ByteBuf,包括所有数据、读写索引和标记。它和原始 ByteBuf 共享相同的数据存储。
- copy():
- 创建 ByteBuf 的深拷贝,包括所有数据。新的 ByteBuf 与原始的相互独立,它们不共享数据。
- capacity() 和 ensureWritable():
- capacity() 方法返回 ByteBuf 的当前容量。ensureWritable(int) 确保 ByteBuf 有足够的空间写入指定数量的数据,如有必要,它会扩展 ByteBuf 的容量。
零拷贝机制
在继续深入了解bf之前,我们先了解一下bf中用到的一个概念—零拷贝。
零拷贝(Zero-Copy)是一种计算机编程技术,它最大限度地减少数据在系统中的复制次数,从而提高数据处理的效率。在传统的数据传输方法中,数据经常在不同的系统缓冲区之间进行多次复制,这不仅消耗 CPU 资源,还增加了延迟。零拷贝技术通过减少这些复制操作来解决这个问题。
使用零拷贝可以为我们带来如下几个优势:
- 减少内核空间与用户空间之间的数据拷贝:
- 在传统的 I/O 操作中,数据通常从内核空间复制到用户空间(或反向),零拷贝技术可以直接在内核空间操作数据,避免了这种内核/用户空间之间的拷贝。就比如我要发送数据的时候,可能需要从内核拷贝到用户,用户在拷贝到网络缓冲区,然后再发送,这就需要多次的拷贝,但是使用零拷贝机制可以直接将我们的数据拷贝到网络缓冲区。
- 减少上下文切换:
- 传统的数据传输涉及多次上下文切换(用户态和内核态之间)。零拷贝减少了这些切换,因为数据操作更多地在内核空间内完成。
- 减少 CPU 缓存污染:
- 由于减少了数据复制,CPU 缓存不会频繁地被新复制的数据覆盖,这有助于提高 CPU 缓存的效率。
- 提高 I/O 性能:
- 零拷贝技术尤其对于大量数据的 I/O 操作非常有效,可以显著提高数据传输的速度和整体性能。
零拷贝的实现涉及到如下几个概念,不过我并没有打算在这里深入讲解零拷贝,简单有个概念即可:
- 内存映射(Memory Mapped I/O):
- 文件内容被映射到进程的地址空间,从而可以直接在内存中访问文件数据,避免了读写文件内容时的数据复制。
- 发送文件(Sendfile)机制:
- 在网络传输中,sendfile 系统调用允许数据直接从文件缓冲区传输到网络缓冲区,减少了数据在用户空间的中间拷贝。
- 直接 I/O:
- 直接从磁盘读取数据到应用程序的缓冲区,或相反,避免了操作系统缓冲区的使用。
那么为什么我要讲解零拷贝,是因为Netty中大量使用到了零拷贝机制。
在 Netty 的 ByteBuf 中,使用零拷贝技术(如 slice、duplicate 或 CompositeByteBuf)会创建一个新的 ByteBuf 实例,这些实例与原始 ByteBuf 共享相同的数据存储。因此,如果我们修改了原始 ByteBuf 中的数据,那么所有共享这些数据的 ByteBuf 实例中的数据也会发生相应的变化。
import io.netty.buffer.ByteBuf;
import io.netty.buffer.Unpooled;
public class NettyZeroCopyExample {
public static void main(String[] args) {
// 创建一个ByteBuf实例并写入一些数据
ByteBuf buffer = Unpooled.buffer(10);
buffer.writeBytes(new byte[]{1, 2, 3, 4, 5});
// 使用slice创建一个共享同一数据的新ByteBuf实例
ByteBuf slicedBuffer = buffer.slice(0, buffer.readableBytes());
// 修改原始ByteBuf中的数据
buffer.setByte(0, 9);
// 打印两个ByteBuf的内容
printBufferContent("Original Buffer", buffer);
printBufferContent("Sliced Buffer", slicedBuffer);
// 释放ByteBuf资源
buffer.release();
slicedBuffer.release(); // 注意:由于数据是共享的,这里不需要再次释放
}
private static void printBufferContent(String message, ByteBuf buffer) {
System.out.print(message + ": [");
while (buffer.isReadable()) {
System.out.print(buffer.readByte());
if (buffer.isReadable()) {
System.out.print(", ");
}
}
System.out.println("]");
}
}
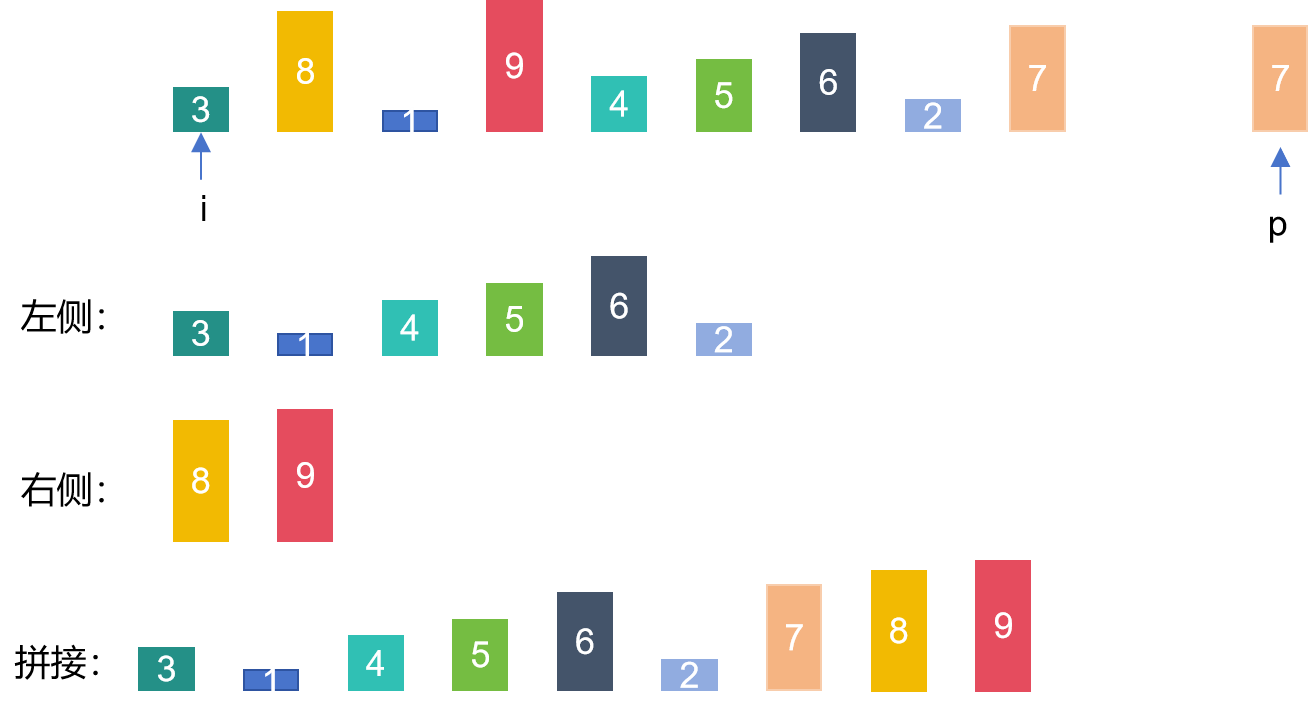
为了进一步展示零拷贝,我会使用到CompositeByteBuf。
这个类再上位机的开发中经常用到。
我们知道,再开发上位机的时候,一般我们的数据格式都是自定义的,一般会有数据头和数据体。而这两个部分其实一般我们都会选择在一起进行发送处理。
但是一般的情况是,我们先制定头,然后头中的部分数据会根据体来决定,所以我们一般需要将他们两个进行拼接处理然后发送,那么如果按照以前我们处理数据的逻辑,就肯定需要进行数据拷贝了。
但是再Netty中这个操作可以非常方便的完成。
import io.netty.buffer.ByteBuf;
import io.netty.buffer.CompositeByteBuf;
import io.netty.buffer.Unpooled;
import java.nio.charset.StandardCharsets;
public class NettyZeroCopyDemo {
public static void main(String[] args) {
// 创建两个ByteBuf实例
ByteBuf header = Unpooled.copiedBuffer("Header", StandardCharsets.UTF_8);
ByteBuf body = Unpooled.copiedBuffer("Body", StandardCharsets.UTF_8);
// 创建一个CompositeByteBuf来组合这两个ByteBuf
CompositeByteBuf message = Unpooled.compositeBuffer();
message.addComponents(true, header, body);
// 遍历CompositeByteBuf并打印内容
for (ByteBuf buf : message) {
byte[] bytes = new byte[buf.readableBytes()];
buf.readBytes(bytes);
System.out.println(new String(bytes, StandardCharsets.UTF_8));
}
// 释放资源
message.release(); // 由于在添加时设置了自动增加引用计数,这里只需释放CompositeByteBuf
}
}
当然,可能你会好奇从代码上看感觉也没感觉用到零拷贝了,那么它的底层真的做到了零拷贝吗?这是我当初的疑问,所以我找了一些资料,总结了一下,大概情况如下:
- 组合而非拷贝:
- CompositeByteBuf 可以将多个现有的 ByteBuf 实例添加到其中,形成一个逻辑上的连续缓冲区。这些 ByteBuf 实例在 CompositeByteBuf 中是按顺序排列的,但它们的内容不会被复制到新的内存位置。
- 内部结构:
- 在内部,CompositeByteBuf 维护了对这些组件 ByteBuf 实例的引用,并在需要时按顺序访问这些组件以进行读取或写入操作。每个组件 ByteBuf 保持其原始数据和状态。
- 读写操作:
- 当对 CompositeByteBuf 进行读取或写入操作时,它会委托给内部的组件 ByteBuf。如果一个操作跨越了多个组件的边界,CompositeByteBuf 会适当地管理这些操作,确保它们在所有相关组件上正确执行。
- 零内存复制:
- 由于数据没有被复制到新的缓冲区,而是通过组件 ByteBuf 的组合来呈现,所以实现了零拷贝。这意味着无论组件 ByteBuf 如何组合,原始数据都保持不变,并且内存复制的开销被消除。
CompositeByteBuf 在需要处理由多个部分组成的复杂消息时特别有用。例如,在网络协议中,一个消息可能由头部和正文组成,这两部分可以分别存储在不同的 ByteBuf 实例中。通过使用 CompositeByteBuf,可以将这些部分逻辑上组合成一个单一的消息,而无需物理上合并它们,从而提高处理效率。
当然,还可以使用Unpooled来实现零拷贝合并。代码也差不多。
import io.netty.buffer.ByteBuf;
import io.netty.buffer.Unpooled;
import java.nio.charset.StandardCharsets;
public class UnpooledWrappedBufferExample {
public static void main(String[] args) {
// 创建两个ByteBuf实例
ByteBuf header = Unpooled.copiedBuffer("Header", StandardCharsets.UTF_8);
ByteBuf body = Unpooled.copiedBuffer("Body", StandardCharsets.UTF_8);
// 使用Unpooled.wrappedBuffer组合这两个ByteBuf
ByteBuf combinedBuffer = Unpooled.wrappedBuffer(header, body);
// 打印组合后的ByteBuf内容
while (combinedBuffer.isReadable()) {
System.out.print((char) combinedBuffer.readByte());
}
// 释放资源
header.release();
body.release();
combinedBuffer.release();
}
}
ok,到此,我想我们已经基本的了解了一下ByteBuf中的几个常用的API的使用以及底层的零拷贝了。
接下来我们来了解一下拆包粘包。
拆包粘包
- 粘包 (Sticky Packet):
- 当两个或多个消息包在接收端被一起读取时,就发生了粘包现象。这通常发生在发送方连续发送了多个数据包,而接收方在读取这些数据时,由于 TCP 的流特性,这些包被一起读取为一个单一的大数据包。
- 拆包 (Packet Fragmentation):
- 拆包则是指一个完整的消息包被分割成多个片段,并且这些片段分别被接收。这可能发生在一个大的数据包在传输过程中被分割为多个较小的数据包,而接收方分多次接收这些小数据包。
对于拆包和粘包,可能会出现如下几种情况:
- 例子 1 - 粘包:
- 假设客户端连续发送了两个数据包 A 和 B。由于 TCP 的字节流特性,接收方可能一次接收到一个合并的数据包 AB。这就是粘包。
- 例子 2 - 拆包:
- 假设客户端发送了一个大的数据包 C。在接收方,这个数据包可能被拆分为两个较小的数据包 C1 和 C2 分别接收。这就是拆包。
- 例子 3 - 同时发生:
- 客户端连续发送了三个数据包 D、E 和 F。接收方可能一次性接收到一个合并的数据包 DE,然后再接收到一个单独的 F,或者接收到拆分的 D1 和合并的 EF。
而拆包和粘包由许多原因可能会导致
- TCP 的流式传输:
- TCP 是一种面向流的协议,它不保留消息的边界。这意味着 TCP 协议在发送数据时,可能会基于网络状况将多个小的消息合并为一个大的数据包发送,也可能将一个大的消息分割成多个小的数据包发送。
- 接收缓冲区大小:
- 接收方的缓冲区大小也会影响拆包和粘包。如果缓冲区较小,一个大的消息可能被分成多次读取,导致拆包。如果缓冲区较大,多个小的消息可能一次性被读取,导致粘包。
而拆包和粘包也会导致很多的问题。
- 数据解析困难:
- 拆包和粘包使得消息的边界变得模糊,这对于需要保持消息完整性的应用来说是一个问题,因为接收方无法确定何时一个消息结束,另一个消息开始。
- 逻辑处理复杂:
- 应用程序需要实现额外的逻辑来处理不完整的消息或多个粘在一起的消息,这增加了数据处理的复杂性。
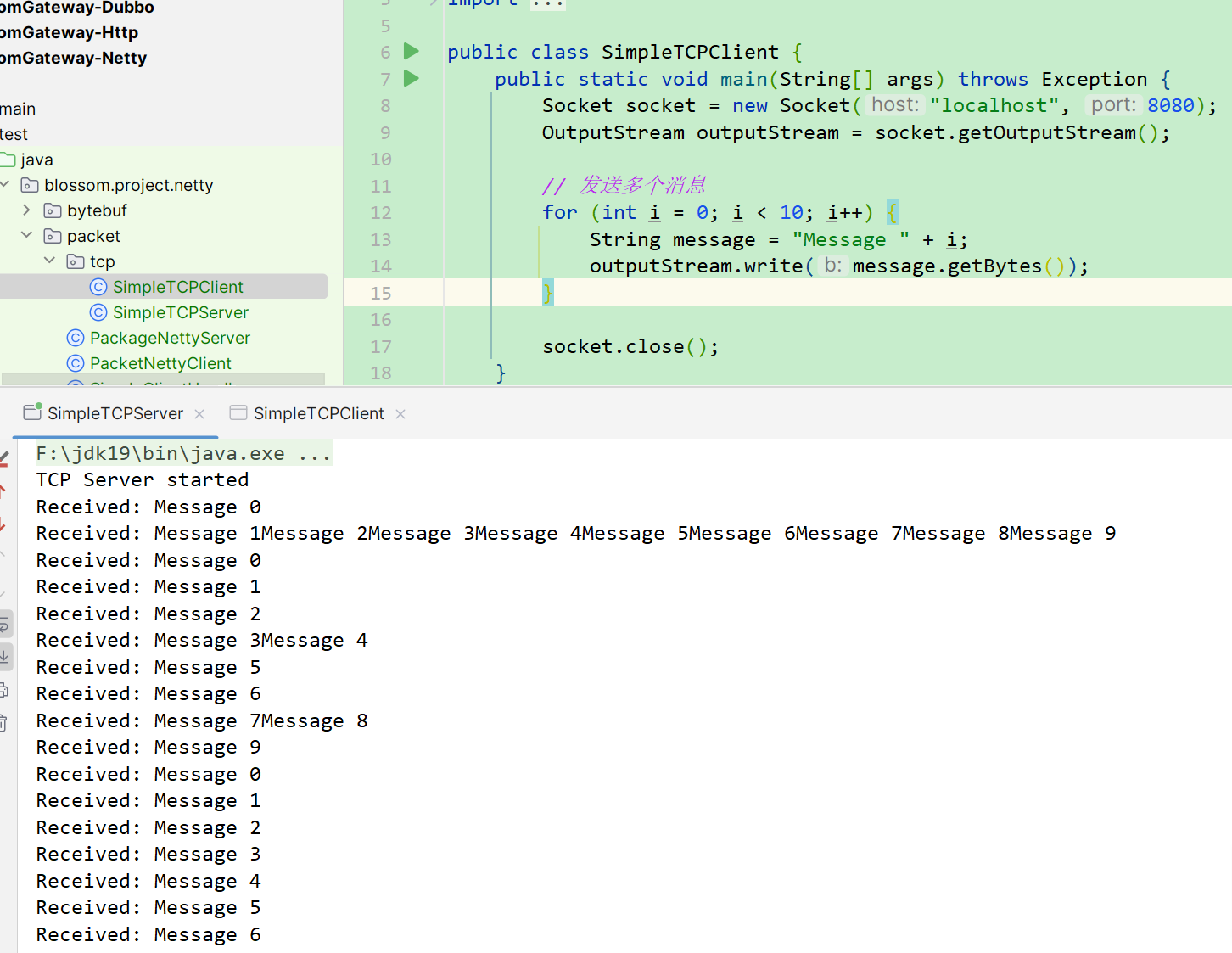
接下来我们首先演示一个基于TCP协议导致的拆包粘包问题。
这里我们需要用到服务端和客户端的代码。将下面的代码进行执行即可,注意,请先运行服务端。
package blossom.project.netty.packet.tcp;
import java.io.InputStream;
import java.net.ServerSocket;
import java.net.Socket;
public class SimpleTCPServer {
public static void main(String[] args) throws Exception {
ServerSocket serverSocket = new ServerSocket(8080);
System.out.println("TCP Server started");
while (true) {
Socket clientSocket = serverSocket.accept();
InputStream inputStream = clientSocket.getInputStream();
byte[] dataBuffer = new byte[1024];
while (true) {
int readBytes = inputStream.read(dataBuffer);
if (readBytes <= 0) {
break;
}
System.out.println("Received: " + new String(dataBuffer, 0, readBytes));
}
clientSocket.close();
}
}
}
package blossom.project.netty.packet.tcp;
import java.io.OutputStream;
import java.net.Socket;
public class SimpleTCPClient {
public static void main(String[] args) throws Exception {
Socket socket = new Socket("localhost", 8080);
OutputStream outputStream = socket.getOutputStream();
// 发送多个消息
for (int i = 0; i < 10; i++) {
String message = "Message " + i;
outputStream.write(message.getBytes());
}
socket.close();
}
}
运行之后就可以发现,三次不同的运行,有三次不同的效果,这就是拆包粘包的情况出现了。
这里为了不浪费篇幅,就不贴出基于Netty的拆包粘包的代码了。
解决拆包粘包
知道了拆包粘包的概念,我们就得花一些时间去思考如何解决拆包粘包了。
其实我们很容易想到的就是,再一个请求中设定一个长度,这个长度用于记录我们发送的消息的长度,这样子,只要我们拿到了这个消息的长度,就可以用于界定我们这一次消息的范围了。
而对于消息长度的设定,我们可以设定定长,比如每一个消息都是128Byte,也可以考虑在我们的请求头中设定消息的长度,再读取到消息长度对应的字段之后,我们再接着继续读取定长的消息即可。
因此,其实为了解决拆包粘包的问题,我们可以从自定义的协议上入手。
我们设定长度,其实就是为了知道一个消息的结束位置。那么我们也可以参考Redis中AOF的格式。
AOF中包含了,消息的长度、消息分隔符、消息内容。
通过这样子的方式,我们就能很容易的解决拆包粘包问题。
其实再Netty中也已经为我们提供了解决这些问题的方法。
固定长度(Fixed-Length)的消息
在这种方法中,所有消息都被设置为相同的固定长度。如果消息不足固定长度,则可以用空白或其他特定字符填充。再Netty中可以使用FixedLengthFrameDecoder可以实现固定长度。
定界符(Delimiter-Based)协议
在消息的末尾添加特定的定界符来标记消息的结束。例如,可以使用换行符或特定的字符序列作为定界符。
在 Netty 中,DelimiterBasedFrameDecoder 可用于处理基于定界符的协议。
长度字段(Length-Field-Based)协议
在消息的头部添加一个长度字段来指示消息体的长度。消息接收方首先读取长度字段,然后根据这个长度来读取相应长度的数据。
在 Netty 中,LengthFieldBasedFrameDecoder 是处理基于长度字段的协议的理想选择。
其中,最后一种基于长度字段的使用最频繁。因此我着重介绍一下对他的了解:
首先就是先知道这个解码器对应的参数是什么意思。
- maxFrameLength: 指定可以接收的最大帧长度。如果帧长度超过此值,将抛出 TooLongFrameException。
- lengthFieldOffset: 长度字段的偏移量。这是指定长度字段开始的位置距离整个数据包开始的位置的字节数。
- lengthFieldLength: 长度字段的长度,即存储长度数据的字节数。
- lengthAdjustment: 用于调整长度字段的值,可能需要根据协议的不同而做出调整。
- initialBytesToStrip: 接收到数据包后,需要跳过的初始字节数,通常用于去除长度字段。
为了便于你理解这些参数。我们假设自定义了一个协议格式。
在这个协议中,每个消息由一个4字节的长度字段开头,该字段指示随后实际数据的长度(N字节)。
针对这个协议,我们将设置 LengthFieldBasedFrameDecoder 的参数如下:
- maxFrameLength (1024): 假设最大帧长度为 1024 字节。
- lengthFieldOffset (0): 长度字段从每个数据包的开始位置算起,所以偏移量是 0。
- lengthFieldLength (4): 长度字段占用 4 字节。
- lengthAdjustment (0): 长度字段仅包含数据部分的长度,所以不需要调整。
- initialBytesToStrip (4): 读取时跳过长度字段本身。
那么我们编写代码的时候,大概内容就是:
public class CustomProtocolServer {
public static void main(String[] args) throws Exception {
// ... EventLoopGroup 和 ServerBootstrap 设置 ...
bootstrap.childHandler(new ChannelInitializer<SocketChannel>() {
@Override
protected void initChannel(SocketChannel ch) {
ch.pipeline().addLast(new LengthFieldBasedFrameDecoder(
1024, 0, 4, 0, 4));
ch.pipeline().addLast(new SimpleChannelInboundHandler<ByteBuf>() {
@Override
protected void channelRead0(ChannelHandlerContext ctx, ByteBuf msg) {
// 处理接收到的数据
System.out.println("Received: " + msg.toString(Charset.defaultCharset()));
}
});
}
});
// ... 绑定端口和启动服务器 ...
}
}
而客户端
public class CustomProtocolClient {
public static void main(String[] args) throws Exception {
// ... EventLoopGroup 和 Bootstrap 设置 ...
ChannelFuture f = bootstrap.connect("localhost", 8080).sync();
String message = "Hello, Netty!";
byte[] bytes = message.getBytes();
ByteBuf buffer = Unpooled.buffer(4 + bytes.length);
buffer.writeInt(bytes.length); // 写入消息长度(4 字节)
buffer.writeBytes(bytes); // 写入实际数据
f.channel().writeAndFlush(buffer);
// ... 关闭连接 ...
}
}